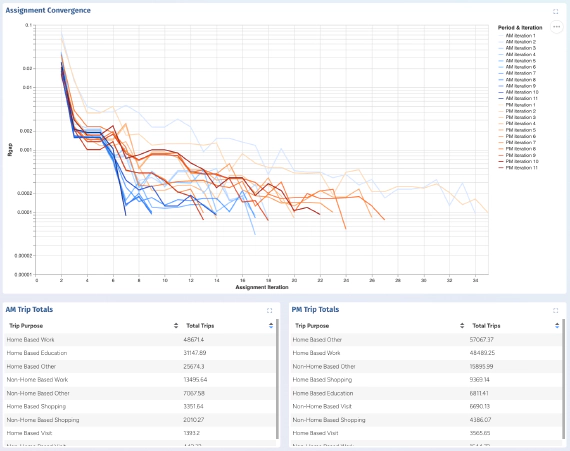
Instant Project Dashboards for AequilibraE
Over the last two months, I have been interning with Outer Loop on the integration of web-based visualization …


Outer Loop was born out of the desire of our founders to do interesting and relevant technical work that contributes back to the field. One of the areas that we do that is via continual development of the open source AequilibraE transport modelling package for Python.
Recently we have begun work on the development of Transit modelling capabilities with the support of FabMob and EGIS. This work has also inspired us to revisit AequilibraE’s traffic assignment to determine whether we can leverage the many recent algorithmic developments in shortest path computation to improve runtime performance. We were lucky enough that the timing worked out to put this forward as a project for the students enrolled in the Summer Internship Program from the School of Mathematics and Physics at the University of Queensland. We were even luckier still to have the talented Jake Moss and Chris O’Brien agree to join us in this journey.
Jake and Chris have started out with an exploration of the AequilibraE codebase where they have already found and fixed a pair of important issues. They have also put together the following benchmarking guide to demonstrate AequilibraE’s current capabilities against a suite of alternate path-finding tools. The aim of this is to give a baseline to guide goal setting for performance improvements and we present it here for others who might be interested in the topic.
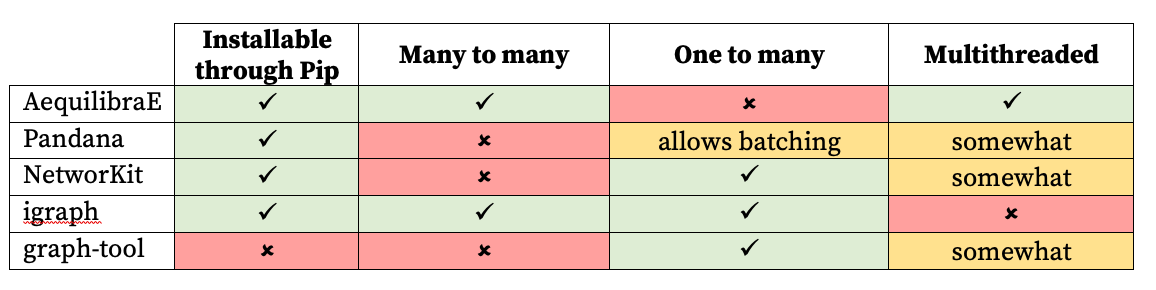
We have identified four alternate packages which contain path-finding capabilities comparable to Aequilibrae: igraph, graph-tools, NetworKit, and Pandana. However, in our early testing we discovered Pandana was not a viable package as it ran two orders of magnitude slower than AequilibraE, and got worse the larger the network was. We believe that this due to a fundamental difference in purpose, Pandana excels at fast point to point path building, but isn’t optimised for one-to-many builds in the same way that the other libraries are. NetworkX was also considered, but being pure-Python means it is also significantly slower than AequilibraE and the other packages we are analysing.
AequilibraE is written in a combination of Python and Cython which is compiled down to C++. The package has a plugin that integrates into QGIS directly, and is generally natively multithreaded (with some exceptions). It has all-to-all, one-to-one and one-to-many pathfinding capabilities that can be used for skimming and direct pathfinding. The pathfinding engine is adapted from SciPy and is an implementation of Dijkstra with a Fibonacci heap written by Jake Vanderplas. In addition to pathfinding, AequilibraE has inbuilt capabilities for traffic assignment with All or Nothing, MSA, and the regular, conjugate and biconjugate Frank-Wolfe algorithms which allows users to execute the entire traffic modelling process within AequilibraE. The package also creates its own topological contraction on the input network where a set of nodes that comprise a contiguous road segment is removed and then replaced by one link which has its properties derived from the aggregate of the removed links, improving path-finding performance.
NetworKit is a general-purpose graph analysis package written in C++ which has a myriad of features and a focus on parallelism and scalability. The software is integrated with other packages in the Python ecosystem such as networkX and Pandas. The Python API allows users to make any type of graph they desire including a set of implementations for dynamic graphs. The package has a large spread of functionalities, from shortest path calculations to applying linear algebra to graph analysis. For our purposes, our examination was centred on the distance sub-module.
NetworKit’s distance API contains many different algorithms for path calculation, many of which we had to Google, such as BFS, A* and Dijkstra, as well as a bidirectional search. There are also parallels for dynamic graphs. Extending on the basic algorithms, there are options for one-all, all-to-all, multiple targets, and all simple path calculations that come out of the box. Our testing used NetworKit’s Dijkstra implementation.
igraph is a C library designed for advanced network analysis and general graph theory computation which exposes interfaces in R, Python, Mathematica, and C/C++. It has a focus on portability and ease of use which shines through with their comprehensive documentation and ease of installation. The large scope and maturity of the project offer great compatibility with existing projects and other libraries, its integration with Pandas dataframes made the conversion from AequilibraE’s internal representations trivial.
Amongst igraph’s extensive Python interface there are two functions of interest to our analysis: get_shortest_paths and distances. get_shortest_paths is igraph’s interface to their implementation of Dijkstra’s algorithm for constructing the path from a single node to a list of targets. Distances is equivalent to AequilibraE’s skim method and constructs a skim matrix from a set of origins to a set of destinations using Dijkstra using a binary heap with early exit.
Graph-tool is a self-proclaimed “efficient Python module for manipulation and statistical analysis of graphs”. It is implemented in C++ and based entirely on the Boost Graph Library. Consequently, it cannot be installed through pip. Graph-tool does not run natively on Windows and only has official packages in in a few repositories, severely limiting the compatibility of the package. For our use we had to create a Docker container and run python through Anaconda to get a working installation of Graph-tool.
Graph-tool has no method to directly skim a network, however it does have a set of one-to-many shortest path tools. In our testing, we used the shortest_distance` function. Unlike other libraries, graph-tool is also able to return the predecessors for the found paths which could allow efficient building of the network skim by removing repeated work.
While graph-tool can be built with OpenMP for multithreading capabilities, the shortest_distance method is not parallelised. To achieve similar multithreading to AequilibraE, Python’s multiprocessing could be used, however this would present issues with shared memory and the inherent copying of data that is required.
In preparing our benchmarks we used the topologically contracted graph (as created by AequilibraE) and translated it into a format consistent with the API of each package. Given that some packages were natively multi-threaded and others weren’t, the benchmarks were executed with one core, making the runtime dependant on the algorithm’s efficiency alone. To exercise the path building of each algorithm we measured the runtime taken to form the centroid-to-centroid cost matrix. The benchmarks were executed on transport modelling networks ranging from single city to state-wide models, including one imported directly from OSM using AequilibraE’s importer.
This was all executed on a docker container running under Ubuntu on an r5.large instance with a Xeon 8259CL CPU. Each library was tested with three replications and two iterations to control for random variations in system resources.
The three models used for benchmarking were,
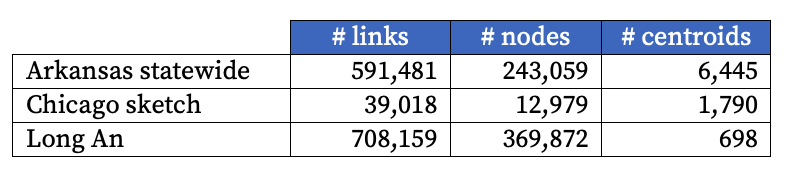
Using AequilibraE’s graph compression the number of links and nodes was reduced by up to a factor of 5x and 6x in the LongAn model. To level the playing field, all benchmarking was performed on the compressed graph generated by AequilibraE. Compression was not benchmarked.

The minimum runtime for each of the algorithms is shown in the table and graph below. This was chosen as it is the most representative of the algorithm’s potential performance; any larger times would be due to variations in system resources. Results have also been normalised to time per 1000 origins to allow readers to extrapolate to their own transport models.
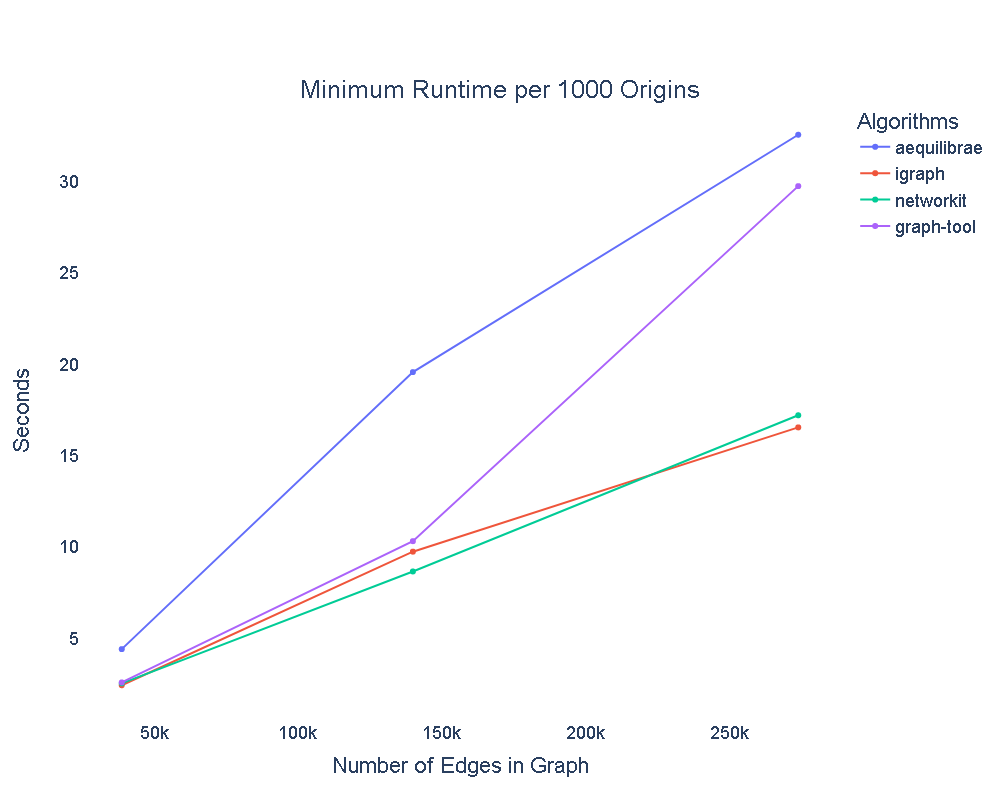
The immediate observation is that while AequilibraE is slower than all of the other contenders, it is within shouting distance - not bad for a home-grown transport modelling package competing against specialised path-building packages. It also demonstrates that there is still significant scope for improvement in the package.
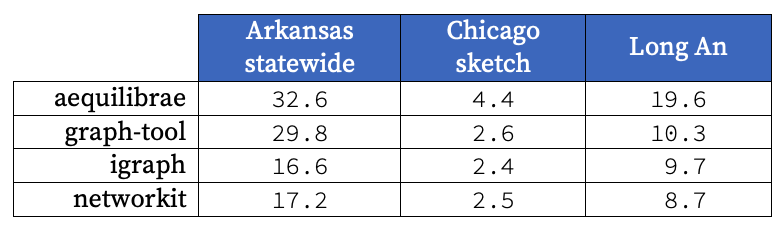
A curious result from this analysis is that we observed the opposite of the published work from graph-tool’s comparison against igraph. We believe this may be due to the fact that the “[PGP web of trust](http://en.wikipedia.org/wiki/Web_of_trust” network that was used in their analysis is a denser network (39,796 vertices and 301,498 edges) when compared to the road networks we tested on. We feel this highlights that the characteristics of a network can have a significant impact on the performance of path finding algorithms.
We also observed that graph-tool seems to deteriorate at a faster rate than the other packages with increases in the size of the network.
Our aim for the remainder of the SMP internship project is to further isolate the characteristics of these algorithms that give them the runtime edge and incorporate as many as possible into Aequilibrae. The two packages we will focus our investigation on are NetworKit and igraph as they are consistently ~50% faster across all sizes of network. Our initial hypotheses as to why this is are:
They utilise different implementations, specifically a binary heap and a relaxed heap. It is common knowledge (according to Wikipedia) that Fibonacci heaps are not efficient in practice due to the significant overhead in maintaining the Fibonacci Heap ordering that is not included in its asymptotic performance. Smaller per-node memory structure leading to better CPU cache utilisation Use of early exit to stop path building when all centroids are reached Aequilibrae also allows skimming multiple fields (other than just the cost which was minimised) which adds some overhead that isn’t present in the other tools. The skimming requirement also requires that we carry the predecessor links (rather than just the current minimum cost to the node) which potentially increases our memory footprint. The only other package that does this is graph-tool – and this could potentially explain the deterioration with increased network size that it exhibits. Over the remainder of the summer, we will be experimenting and validating these ideas, stay tuned for further posts as we explore this exciting space and hopefully close the performance gap.
All the code for our experimentation is available as a docker container built from the public GitHub repository here. Bug fixes or identification of errors in our methodology will be gladly accepted.
Over the last two months, I have been interning with Outer Loop on the integration of web-based visualization …

Over the past 8 weeks we – Evelyn Bond and Tyler Pearn – have been working with Outer Loop as part of the University of …
