Instant Project Dashboards for AequilibraE
Over the last two months, I have been interning with Outer Loop on the integration of web-based visualization …


Photo by Julia Joppien

As part of a wider effort to improve the overall performance of the AequilibraE transport modelling package, we have recently identified that the current performance of the traffic assignment module lags other general purpose path finding libraries.
From profiling it was obvious that this process was bottlenecked on the retrieval of elements from the heap structure that is used to underpins the Dijkstra algorithm. During the second half of the UQ SMP Summer internship program, our two amazing interns, Chris and Jake, dug in to the codebase to test various alternative heap structures and to significantly bridge this performance gap.
Their excellent work is presented in this white paper. They cover what the heap is, why it’s important for Dijkstra, how to efficiently implement it, making best use of the cache and the Cython compiler. In this post however, I want to share a few of the most interesting highlights.
The first is that the project was very successful and as a result the overall runtime required to run traffic assignment with skimming using Aequilibrae has decreased by approximately 60% (i.e. 2.5 times faster). This is a phenomenal result and will result in significant benefits for all users of Aequilibrae well into the future.
The second is just how much of a difference the choice of heap implementation makes to the overall runtime. In the following plot, the minimum runtime (normalised to seconds per 1000 zones). While performance was consistently linearly related to the network size, the Fibonacci heap (which was originally used in Aequilibrae) underperforms all comers by a factor of approximately 2.
While the Fibonacci heap’s performance is theorised to scale better for larger networks, the above chart includes results for an Australia wide model with over 3 million road segments that seems to show the opposite is true: the Fibonacci’s relative performance got worse for larger networks.
Our analysis showed that a potential explanation for this is that the size of the heap does not grow significantly as the size of the project does. Namely, the number of open nodes in the heap was not linearly related to the over overall network size, for example the Australia wide network had a peak open node size of roughly double the Arkansas network, despite having over 10 times more edges.
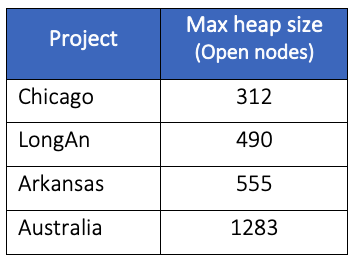
This represents the “cloud” of reachable nodes currently being considered within the Dijkstra algorithm. This leads to the following key observation:
Due to the relative sparsity of transport network graphs, the set of open nodes does not grow fast enough for the asymptotic behaviour of the Fibonacci heap to become significant.
A common theme observed in studies where Fibonacci heaps did perform well was densely connected graphs, such as social networks, where there were often 10s or 100s of connections per node.
I’d like to further thank Chris and Jake for their hard work during the summer and reiterate what an incredible difference they have made to the state of AequilibraE’s assignment capabilities. I have no doubt they will move from strength to strength, and I look forward to seeing what they accomplish in the future.
Over the last two months, I have been interning with Outer Loop on the integration of web-based visualization …

Over the past 8 weeks we – Evelyn Bond and Tyler Pearn – have been working with Outer Loop as part of the University of …
