Instant Project Dashboards for AequilibraE
Over the last two months, I have been interning with Outer Loop on the integration of web-based visualization …

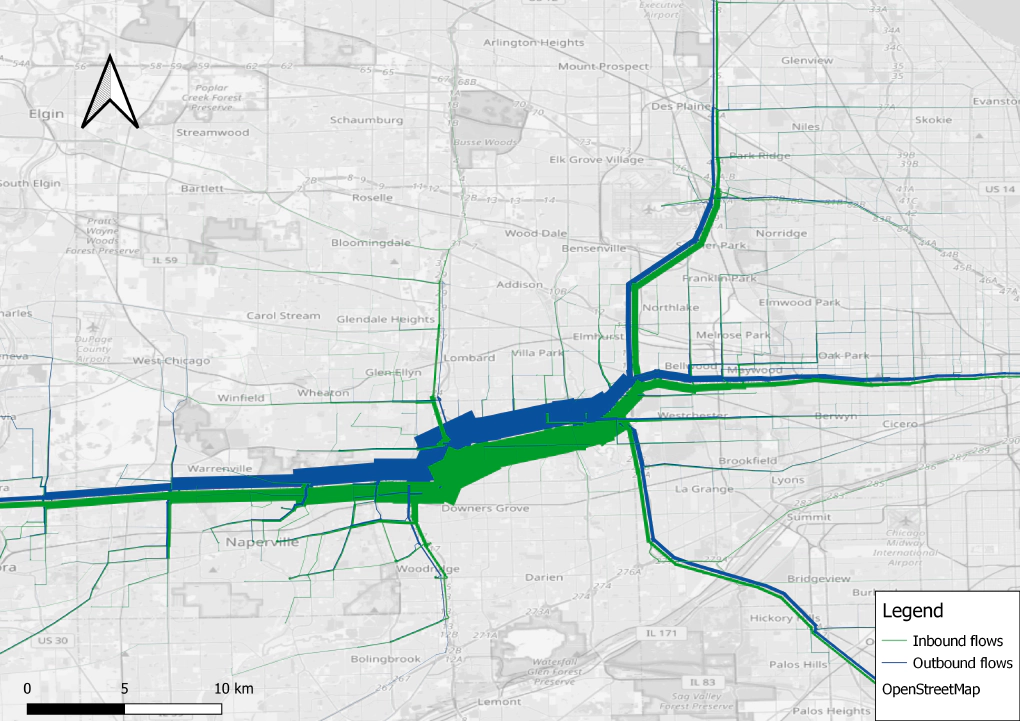

In our continued effort of improving the capabilities of the AequilibraE transport modelling package, we have just released a new version of the software, which incorporates an important new feature that had been years in the making: Select-Link Analysis.
As if significantly improving AequilibraEs path-finding performance were not enough, our two amazing interns, Chris and Jake, created a robust implementation of select-link analysis in the final weeks of their UQ SMP Summer internship program with Outer Loop, which is part of the recent release 0.8.1 of AequilibraE.
For now, the Select-Link Analysis feature allows for queries of a single link or an arbitrarily long set of alternative links (i.e. any link traversed in the set would trigger the selection), where the user is always able to select link and direction for a query, allowing for detailed results on the demand using each one of a link’s direction.
Their implementation of Select-Link Analysis, which was based on substantial internal discussion and thorough performance analysis, includes the generation of select-link matrices & select-link flows, and has been carried through multi-class assignment and AequilibraE’s advanced equilibration algorithms with impressive performance across different network sizes, hardware specifications and number of simultaneous queries.
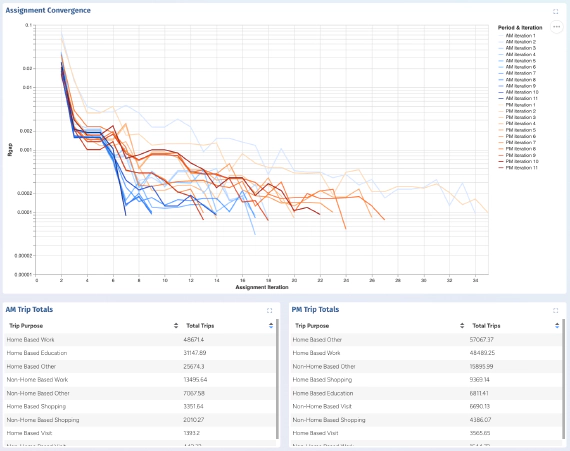
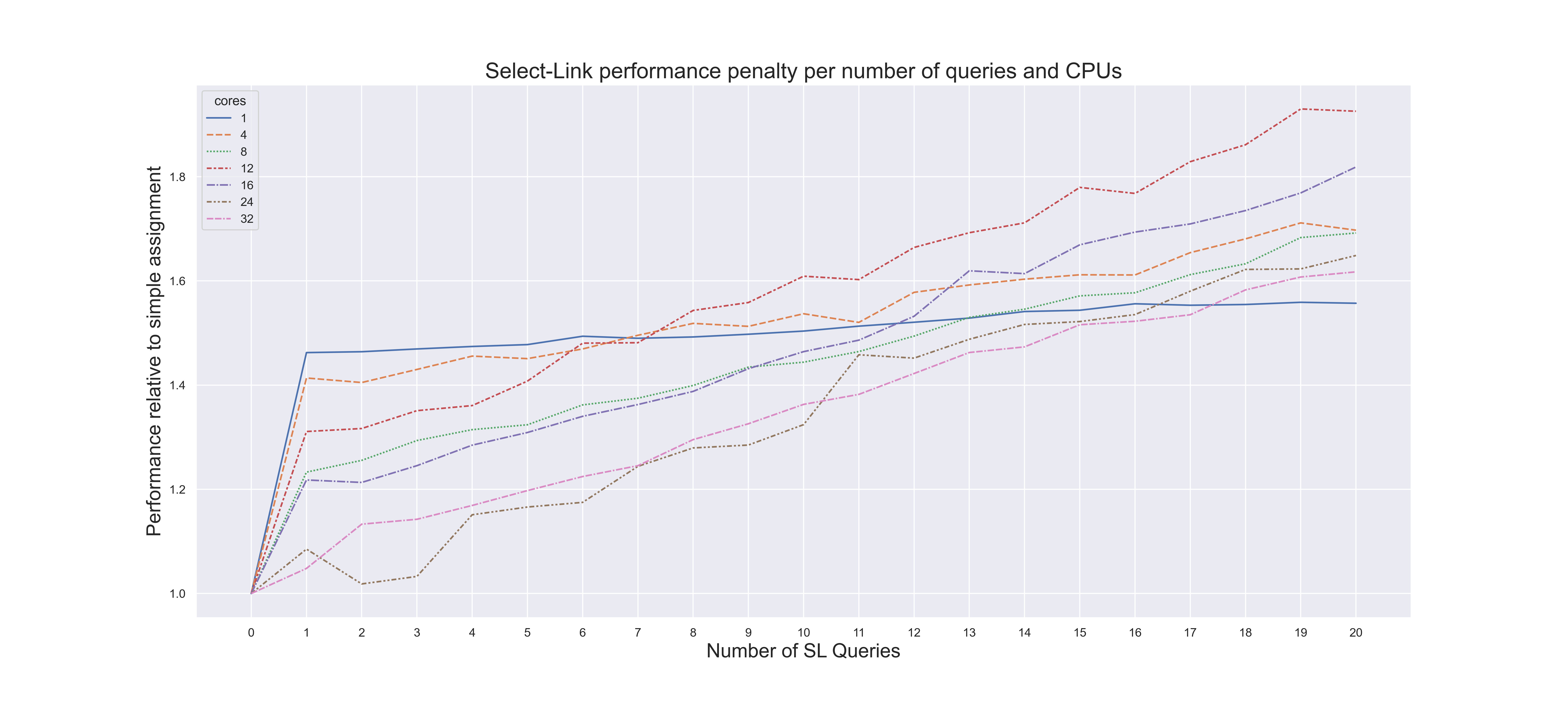
The implementation allows for running multiple queries at once, which takes advantage of only requiring a single path building phase. Taking the Chicago-Sketch model as an example with a Bi-conjugate Frank-Wolfe assignment, we see a pretty consistent performance characteristics as we grow the number of queries.
In the following chart we show the performance, expressed as a factor of the runtime without any Select Link queries, for varying levels of multi-threading. In single threaded mode there is an immediate 50% jump in runtime for the first query (reflecting the additional work required to perform this type of analysis) but the marginal cost of subsequent queries is negligible. As the multi-threading level increases - other factors come into play and the additional memory requirements of extra queries becomes more of an issue resulting in a linear response of between 1.0x to 1.6x (20 queries) for the 32-thread case.
A more complete set of benchmarking results with the code that generated it will be available with the new AequilibraE documentation, currently under development but, in the meantime, how do you plan to include this new feature of AequilibraE into your workflow?
Over the last two months, I have been interning with Outer Loop on the integration of web-based visualization …

Over the past 8 weeks we – Evelyn Bond and Tyler Pearn – have been working with Outer Loop as part of the University of …
